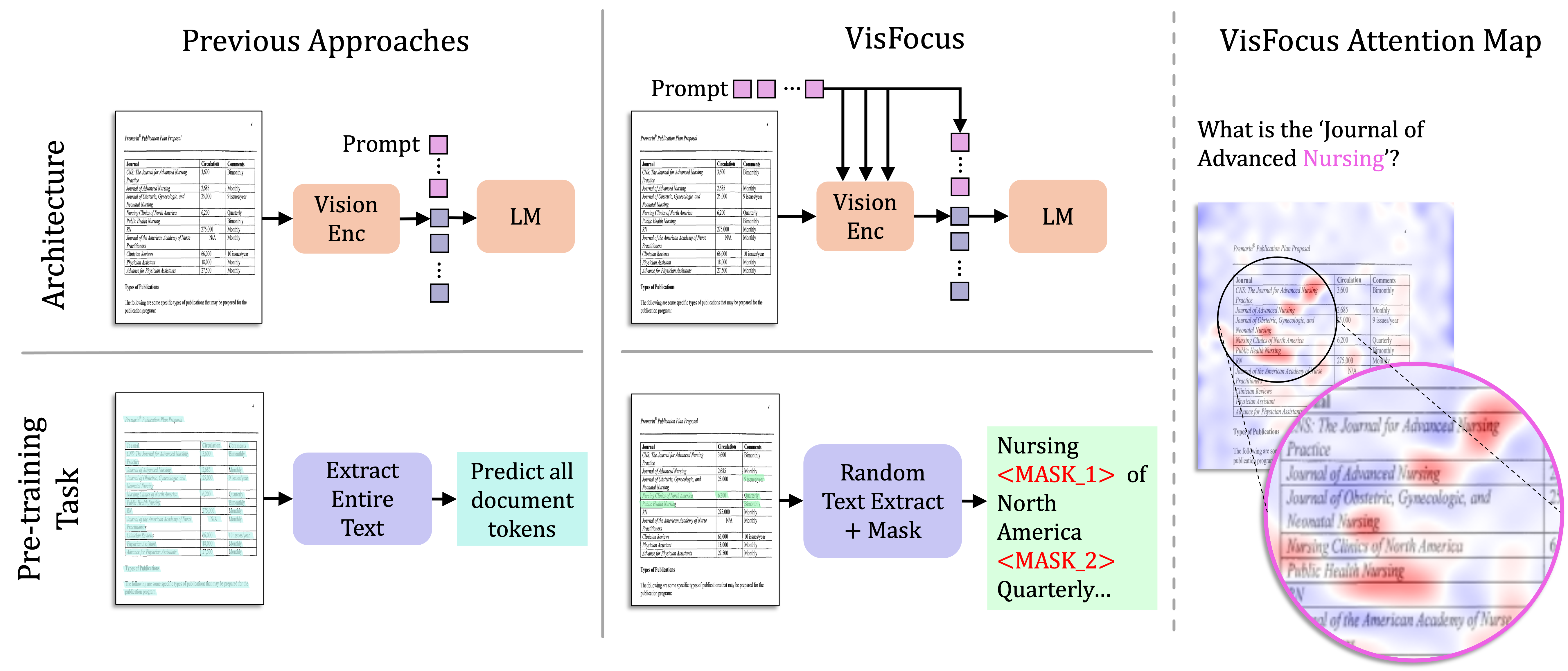
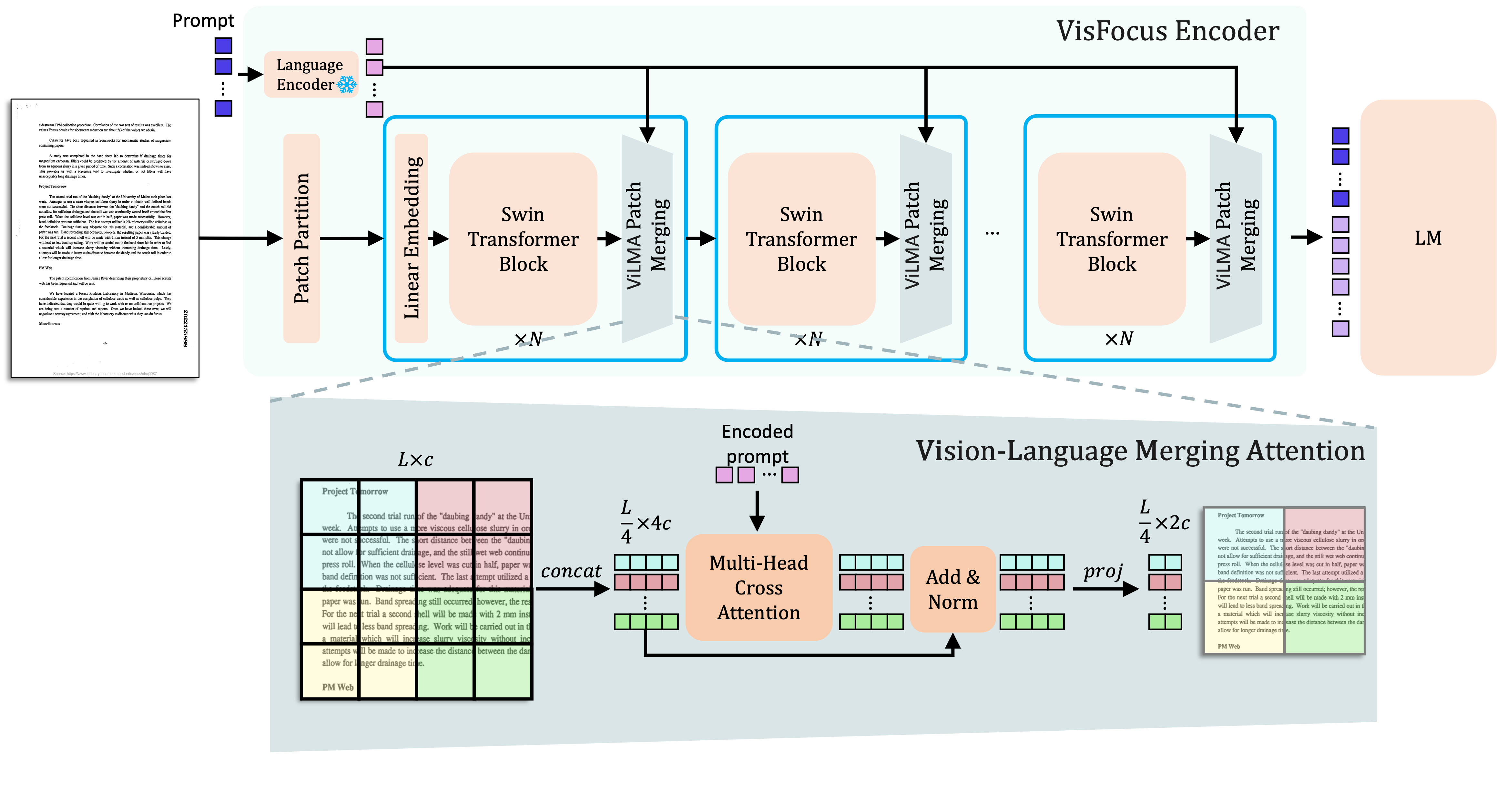
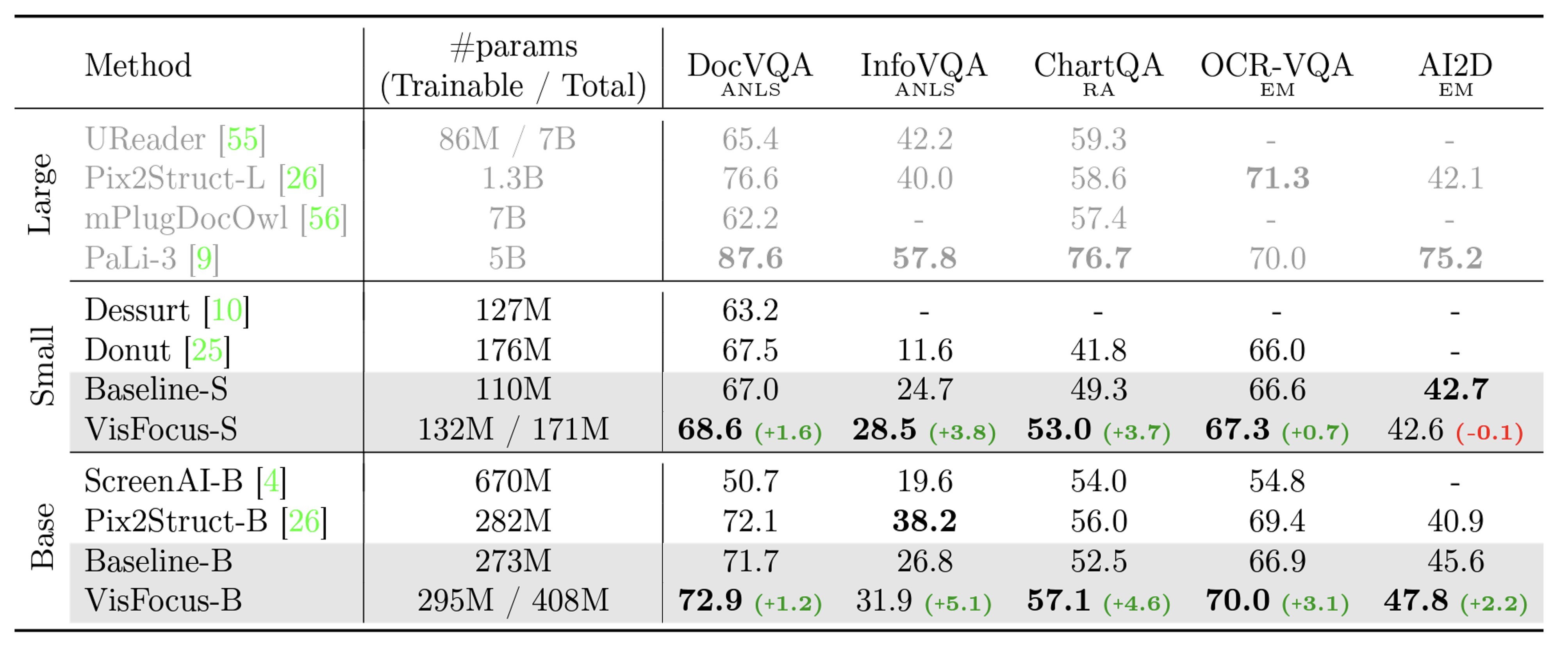
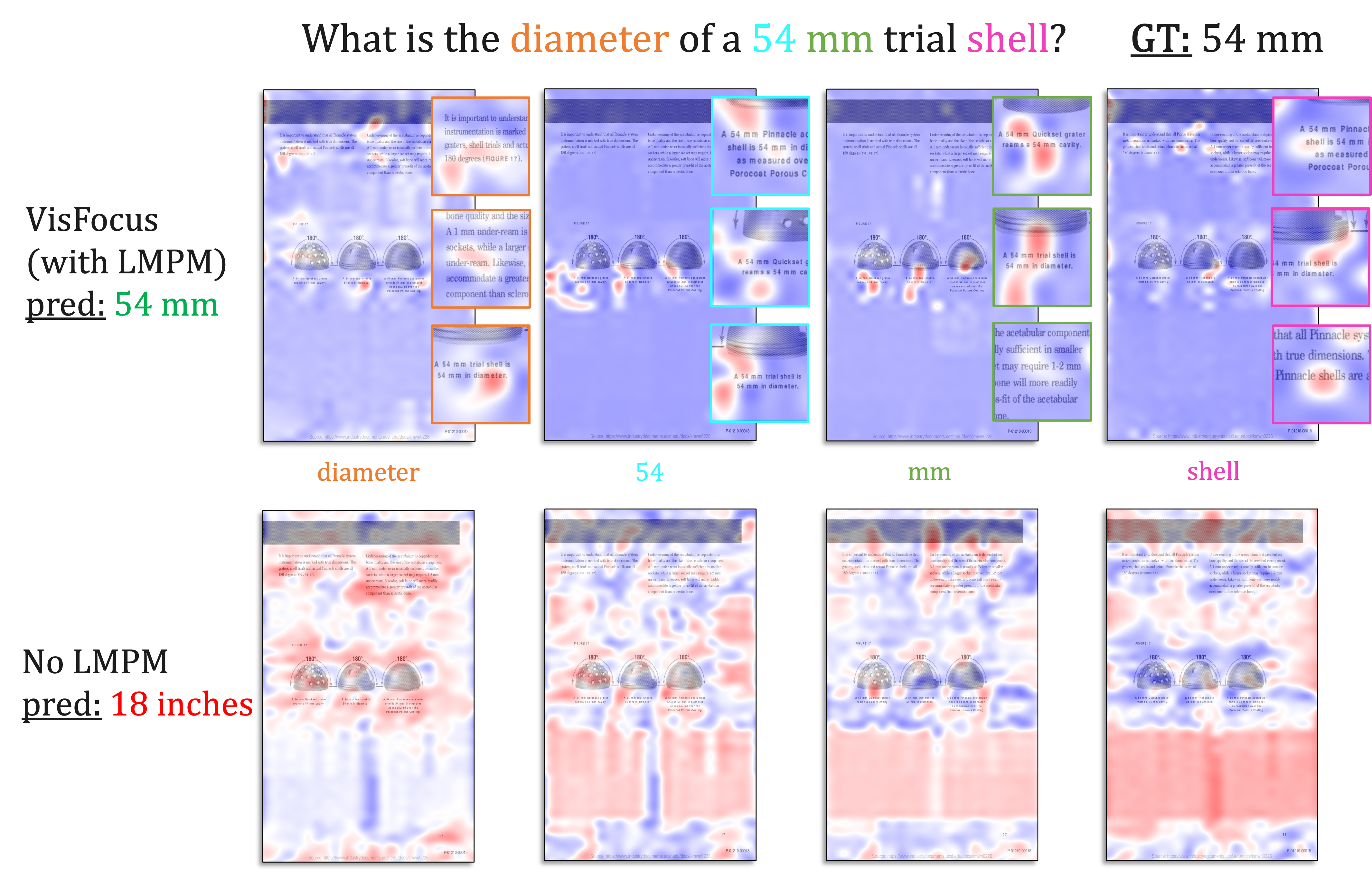
VisFocus:
Prompt-Guided Vision Encoders for OCR-Free Dense Document Understanding
ECCV 2024
1Reichman University 2Amazon AWS AI Labs